外行学 python 爬虫 第三篇 内容解析


.
从网络上获取网页内容以后,需要从这些网页中取出有用的信息,毕竟爬虫的职责就是获取有用的信息,而不仅仅是为了下来一个网页。获取网页中的信息,首先需要指导网页内容的组成格式是什么,没错网页是由 HTML「我们成为超文本标记语言,英语:HyperText Markup Language,简称:HTML」 组成的,其次需要解析网页的内容,从中提取出我们想要的信息。
HTML
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。HTML是一种基础技术,常与CSS、JavaScript一起被众多网站用于设计网页、网页应用程序以及移动应用程序的用户界面[3]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。HTML描述了一个网站的结构语义随着线索的呈现,使之成为一种标记语言而非编程语言。
以上内容摘自维基百科,它将网页的组成做了一个简单且明确的解释,从中我们知道 HTML、CSS、JavaScript 是一个网页的重要组成部分。但是对于一个爬虫来说它需要关注的仅仅只是 HTML,无需过多关注 CSS 和 JavaScript。
CSS 用于网页的显示格式,爬虫不关注显示的格式。JavaScript 主要用于动态加载内容,当前可暂不关注。
HTML 文档主要有 HTML 元素「或者标签」组成,常用的 HTML 标签主要有以下几种:
- <html> 用来定义一个 HTML 文档。
- <head> 用来定义 HTML 文档的信息。
- <body> 定义 HTML 文档的主体。
- <h1> 到 <h6> 定义 HTML 标题。
- <form> 定义 HTML 文档表单。
- <p> 定义一个段落。
- <a> 定义一个超文本连接。
- <div> 定义文档中的一个节。
HTML 标签远不止上面的这几种,这里只是列出了常见的几种,大家可以在网上找到很多这方面的内容「从网络上找到自己想要的内容,也是一种重要的能力」。
除了标签以外,属性也是 HTML 的一个重要组成部分。属性以“名称-值”的形式成对出现,由“=”分离并写在开始标签元素名之后,对每个标签的显示方式及显示状态进行控制。常用的属性主要有以下几种:
- id 属性为元素提供了在全文档内的唯一标识。它用于识别元素,以便样式表可以改变其表现属性,脚本可以改变、显示或删除其内容或格式化。
- class 属性提供一种将类似元素分类的方式。常被用于语义化或格式化。
- style 属性可以将表现性质赋予一个特定元素
- title 属性用于给元素一个附加的说明。 大多数浏览器中这一属性显示为工具提示。
我们通过 HTML 文档中的标签和属性来确定一个内容的位置,从而获取我们需要从网页上读取内容。
网页内容的解析
网页实际上就是一个 HTML 文档,网页内容的解析实际上就是对 HTML 文档的解析,在 python 中我们可以使用正则表达式 re,BeautifulSoup、Xpath等网页解析工具来实现对网页内容的解析。这里主要介绍 BeautifulSoup 的使用。
今天主要介绍 BeautfulSoup 的以下内容:
- string、strings 和 stripped_strings: BeautifulSoup 通过这三个属性来获取 Tag 的内容。
- find 和 find_all:搜索当前 Tag 及其所有子节点,判断其是否符合过滤条件。
如果一个 Tag 仅有一个子节点有内容「NavigableString 类型子节点」或其只有一个子节点可以使用 string 属性来获取节点内容。若 Tag 包含多个子节点,且不止一个子节点含有内容,此时需要用到 strings 和 stripped_strings 属性,使用 strings 获取的内容会包含很多的空格和换行,使用 stripped_strings 可以过滤这些空格和换行。
通过 find 和 find_all 方法可以过滤掉不需要的字符串对象,使用示例如下:
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import re
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>and
<a class="sister" href="http://example.com/tillie" id="link2">Tillie</a>;
and they lived at the bottom of a well.
</p>
</body>
</html>
"""
soup = BeautifulSoup(html, features='lxml')
print ('---------- string ----------')
print (soup.find_all('title'))
print ('---------- regex ----------')
print (soup.find_all(re.compile('^b')))
print ('---------- list ----------')
print (soup.find_all(['b', 'a']))
print ('---------- True ----------')
print (soup.find_all(True))
print ('---------- function ----------')
def has_class_but_no_href(tag):
return tag.has_attr('class') and not tag.has_attr('href')
print (soup.find_all(has_class_but_no_href))
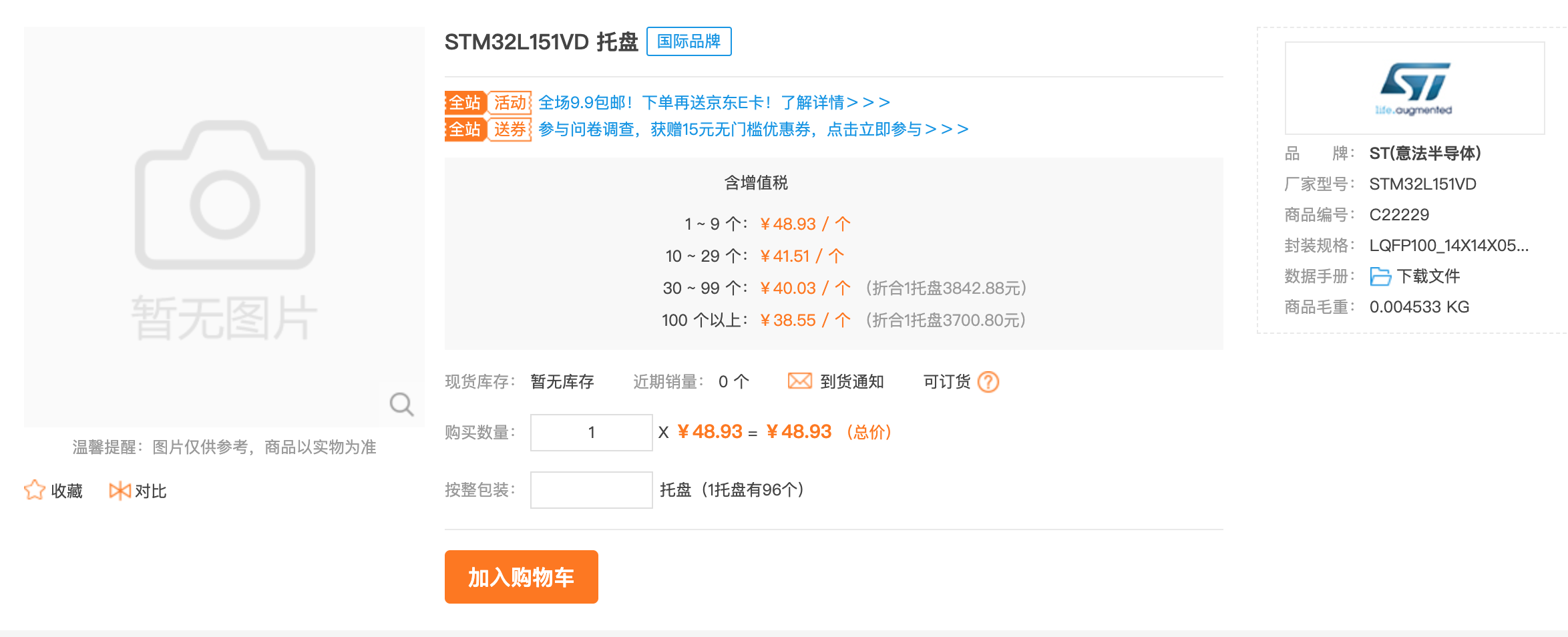 现在需要从以上的网页中解析出品牌、厂家型号、商品编号、封装规格等内容,该怎么做?首先先确定一下它所对应的 HTML 文档的内容
现在需要从以上的网页中解析出品牌、厂家型号、商品编号、封装规格等内容,该怎么做?首先先确定一下它所对应的 HTML 文档的内容
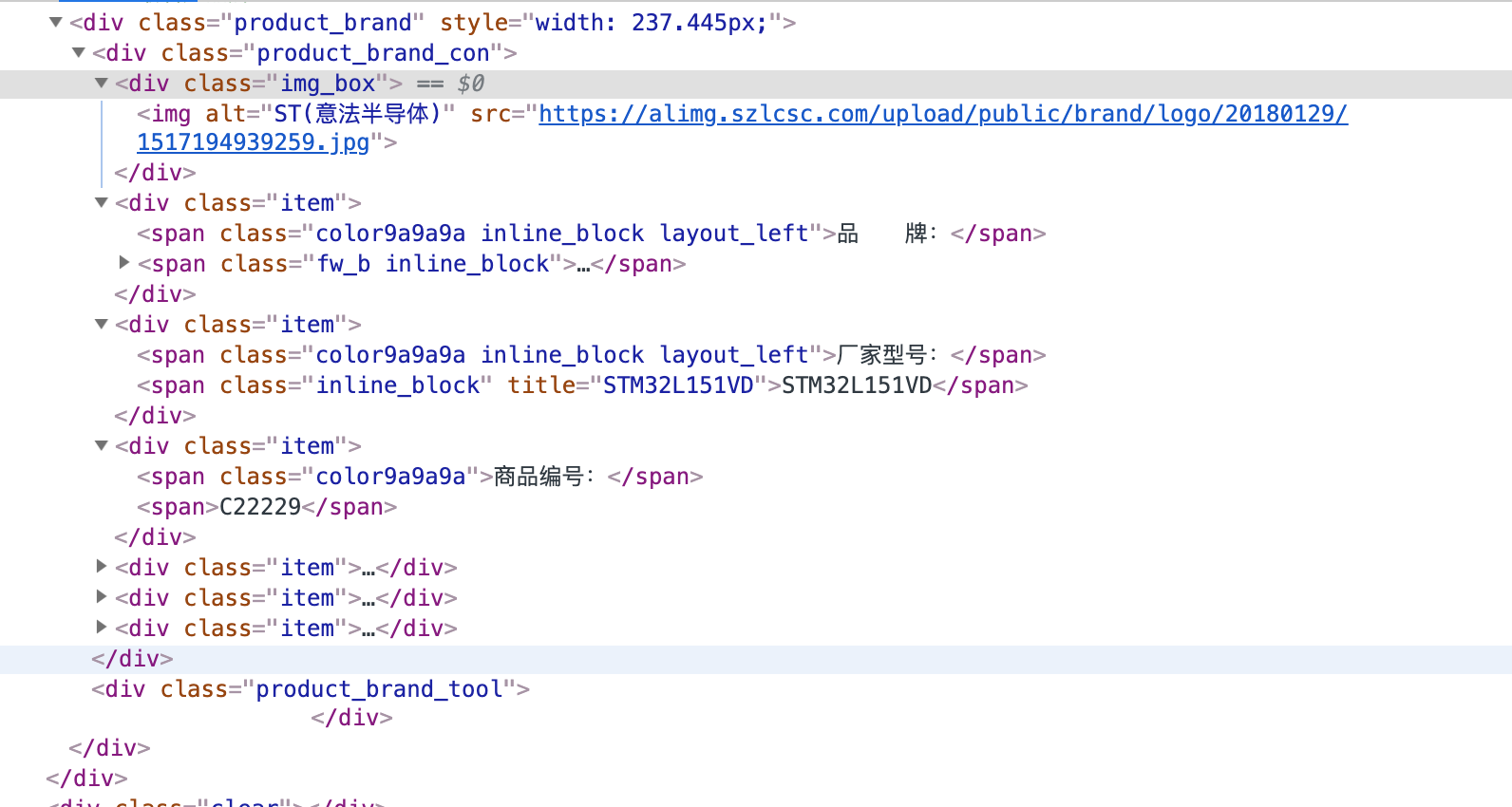
从以上 HTML 文档内容中,可以看出索要获取的内容在 <div class="product_brand_con"> 的小节中,那么需要使用 find 方法从整个 HTML 文档中先把这个小节提取出来,然后使用 find_all 提取出所有的 <div class="item"> 的内容,最后使用 string 属性获取对应的字符串内容。整个过程使用代码表示如下:
brand_dict = {}
soup = soup.find('div', class_='product_brand_con')
if soup is None:
return brand_dict
soup = soup.find_all('div', class_='item')
for item in soup:
str = []
for stri in item.stripped_strings:
str.append(stri)
if len(str) < 2:
continue
if str[0] == '品 牌:':
brand_dict['brand'] = str[1]
if str[0] == '厂家型号:':
brand_dict['model'] = str[1]
if str[0] == '商品编号:':
brand_dict['number'] = str[1]
if str[0] == '封装规格:':
brand_dict['package'] = str[1]
以上代码最终返回一个包含所需内容的字典,若该网页中不存在所需内容将返回一个空字典。
有关 BeautifulSoup 的更多内容,请看 Python 爬虫之网页解析库 BeautifulSoup 这篇文章。
对网页内容的解析实际上就是对 HTML 文档的分割读取,借助于 BeautifuSoup 库,可以非常简单的从复杂的 HTML 文档中获取所需要的内容。
Explore more like this


外行学 python 爬虫 第十一篇 数据可视化
在 外行学 Python 爬虫 第九篇 读取数据库中的数据 中完成了使用 API 从数据库中读取所需要的数据,但是返回的是 JSON 格式,看到的是一串的字符串数据不是很好理解,这篇将介绍如何将数据进行可视化。

外行学 python 爬虫 第十篇 爬虫框架 Scrapy
前面几个章节利用 python 的基础库实现网络数据的获取、解构以及存储,同时也完成了简单的数据读取操作。在这个过程中使用了其他人完成的功能库来加快我们的爬虫实现过程,对于爬虫也有相应的 python 框架供我们使用「不重复造轮子是程序员的一大特点」,当我们了解爬虫的实现过程以后就可以尝试使用框架来完成自己的爬虫,加快开发速度。
Comments