外行学 python 爬虫 第六篇 动态翻页


.
前面几篇文章,初步完成了从网络请求、数据解析、数据存储的整个过程,完成了一个爬虫所需的全部功能。但是通过对数据库中数据的分析会发现数据库中的元件数量比网站上的元件数量少了很多。前面的实现过程通过解析网页中的连接来获取元件详细信息页面,解析出相关的数据。在实际页面中发现有很多的分页现象,通过前面的方式仅能获取第一页的内容,无法获取第二页的内容,这就造成无法爬取所有的页面,最终是获取到的数据比网站上的实际数据小的多。
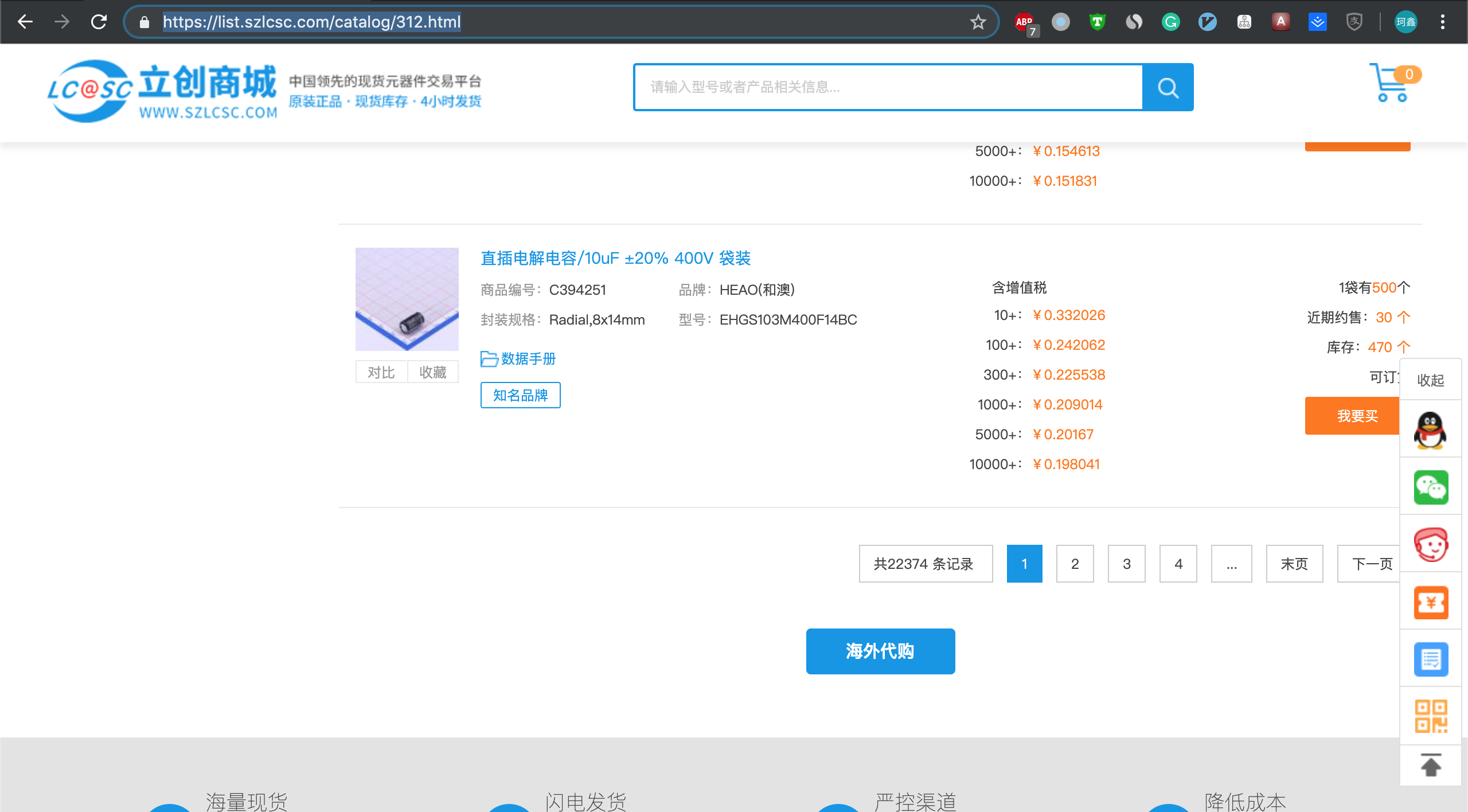
在上面的图片中可以看到数据被分成了很多页面来显示,实际点击下一页按钮,发现地址栏的网址没有发生任何改变,网站使用的 ajax 动态加载技术来实现翻页,此时无法通过网址来区分各个页面的内容。爬取这样的页面有一定的困难,但在 python 中还是有方法可以解决的,一般情况下我们可以通过以下方法来解决:
- 通过 selenium 来模拟浏览器的行为,从而获取翻页的数据。
- 通过分析相应请求,使用 request 来模拟按键的点击效果,从而获取翻页数据。
本节主要通过 request 来模拟网页上的按钮点击来实现翻页。
获取翻页请求网址
翻页请求实际上是一个 post 的过程,我们需要知道 post 的网址及通过 post 请求提交的数据,通过 chrome 浏览器的开发者工具来看下如何实现整个过程。
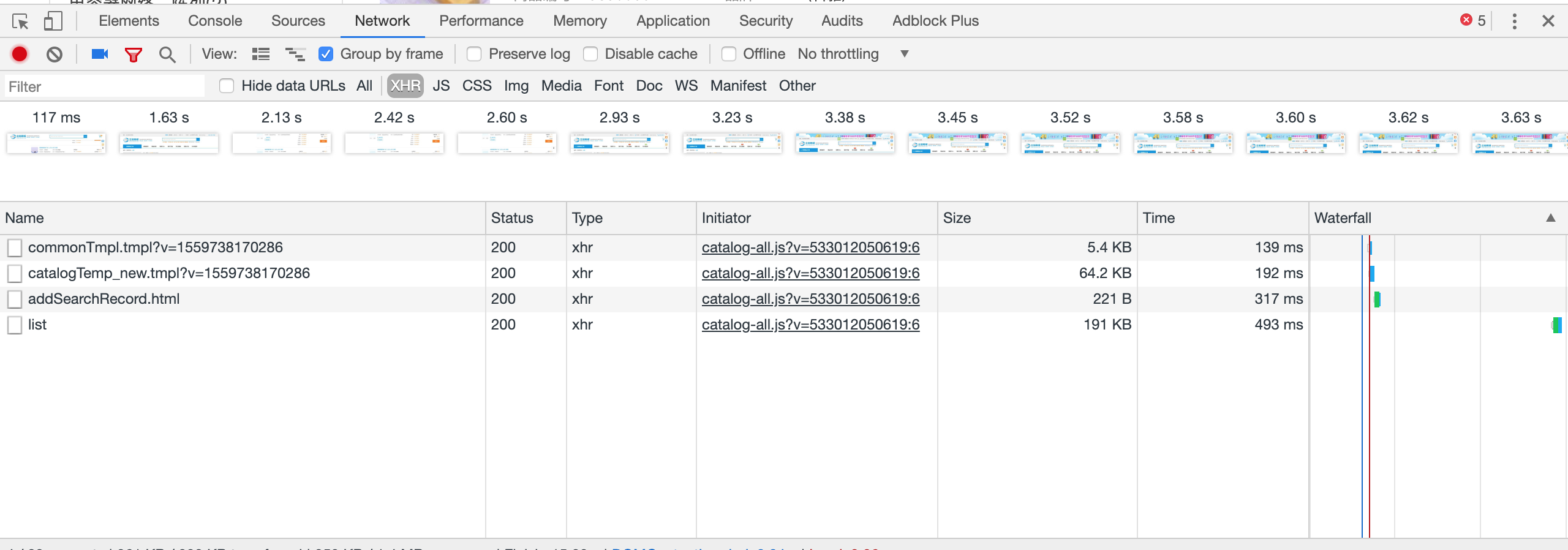 点击下一页后在开发者工具中欧可以看到多了一个 list 的请求,我们先来看一下 list 请求的内容。
点击下一页后在开发者工具中欧可以看到多了一个 list 的请求,我们先来看一下 list 请求的内容。
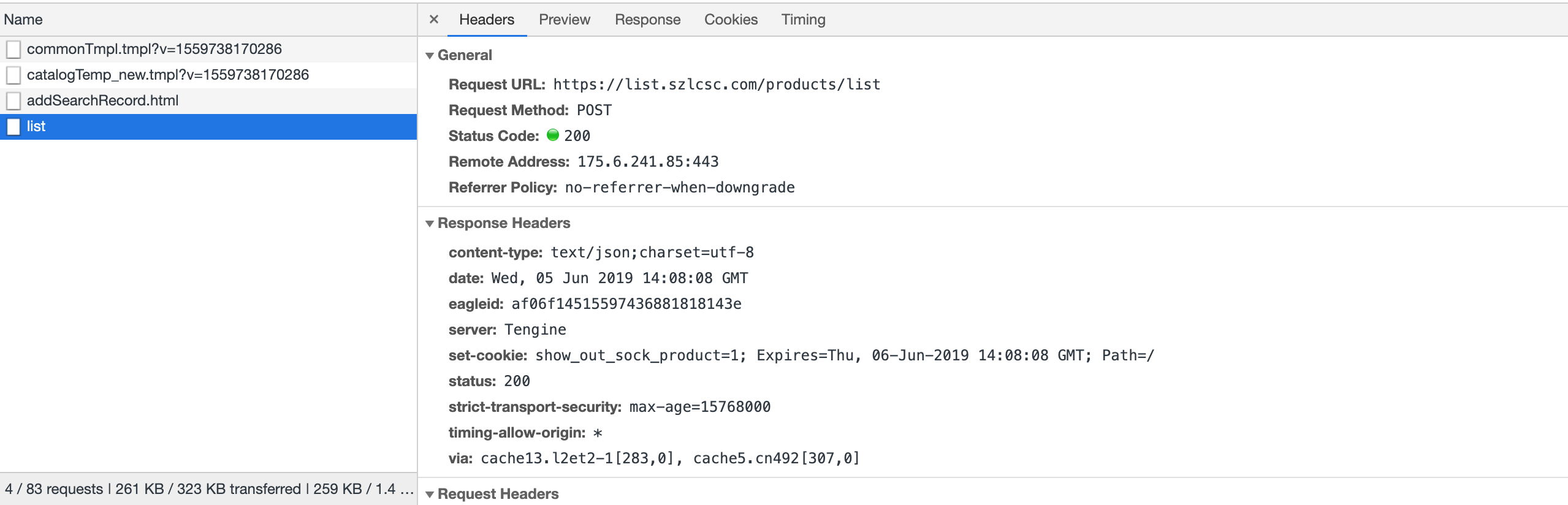
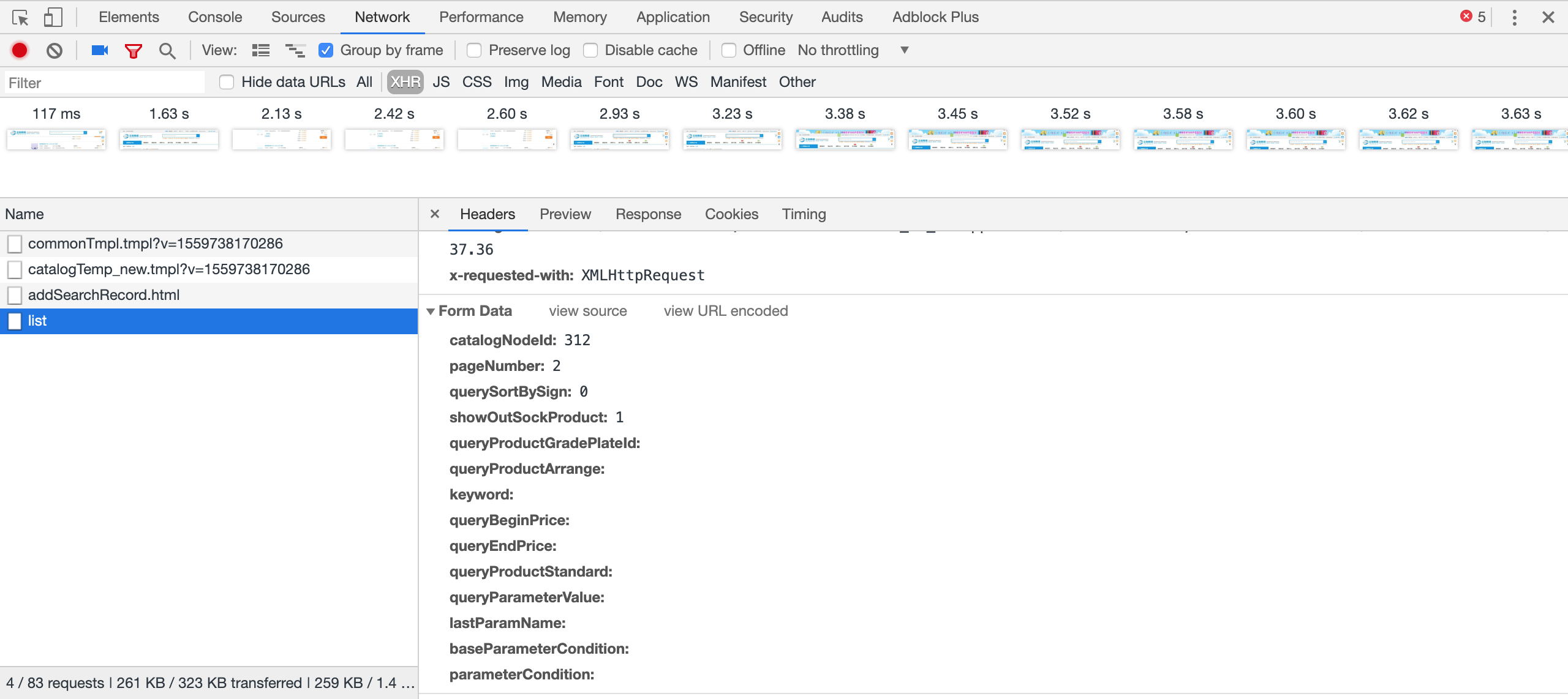 从 list 请求的内容,可以看出 post 的网址为
从 list 请求的内容,可以看出 post 的网址为 https://list.szlcsc.com/products/list,提交的数据主要有以下几个:
'catalogNodeId': '312',
'pageNumber': '2',
'querySortBySign': '0',
'showOutSockProduct': '1'
catalogNodeId 是分类编号这个数字也与我们当前访问的网址的内容一致https://list.szlcsc.com/catalog/312.html,pageNumber 是当前的页码,其他两个可以看做是固定值。
使用 request 模拟浏览器请求
通过 request 携带参数向https://list.szlcsc.com/catalog/312.html提交数据,来获取动态翻页的返回数据,整个代码试下过程如下:
url = 'https://list.szlcsc.com/products/list'
query = {
'catalogNodeId': '313',
'pageNumber': '325',
'querySortBySign': '0',
'showOutSockProduct': '1'
}
fromData = urllib.parse.urlencode(query).encode('utf-8')
response = request.urlopen(url=url,data=fromData, timeout=10)
html = response.read()
data = dict(json.loads(html.decode('utf-8')))
提交的 fromData 数据需要转换为 utf-8 编码。
获取到的数据是 json 格式的需要将其转换为 python 的字典进行分析。获取到的数据内容如下:
{
'ICMemberButton': True,
'ICMemberDiscount': '95',
'isCustomerRemindReplenish': False,
'productRecordList':
[
{
'theRatio': 100,
'productArrange': '-',
'productModel': '0402B821J500CT',
'showLastEncaption': True,
'hasSetProduct': None,
'venditionUnit': '个',
'stockNumberWay': 0,
'hasAnnexPCB': 'yes',
'isChooseModel': None,
'discount': None,
'blankBoardId': None,
'productUnit': '个',
'productName': '820pF(821) ±5% 50V ',
'lightCatalogName': '贴片电容',
'numberprices': '个,100,77,1,-1,1,9,0.018156,10,29,0.013408,30,99,0.012536,100,499,0.011664,500,999,0.011276,1000,-1,0.011085',
'bomMainUuid': None,
'spNumber': 1000,
'priceListSize': 6,
'groupCode': '',
...
由于数据太多,这里仅仅贴出了一部分内容。在这里我们可以解析出各个元件的 productId,通过该编号组合成完整的网址来获取该元件的所有信息。代码如下:
def get_product_item_url(self, current_url):
product_post_url = 'https://list.szlcsc.com/products/list'
query = {
'catalogNodeId': '313',
'pageNumber': '325',
'querySortBySign': '0',
'showOutSockProduct': '1'
}
p1 = re.compile(r'[/]([0-9]*?)[.]', re.S)
category_id = re.findall(p1, current_url)
logger.info(category_id)
page = 0
query['catalogNodeId'] = category_id[0]
query['pageNumber'] = str(page)
while True:
query['pageNumber'] = str(page)
date = urllib.parse.urlencode(query).encode('utf-8')
try:
response = request.urlopen(url=product_post_url,data=date, timeout=10)
html = response.read()
except BaseException as e:
logger.error(2)
return
data = dict(json.loads(html.decode('utf-8')))
productRecordList = data.get('productRecordList')
if not productRecordList:
break
for product in productRecordList:
item_id = product.get('productId')
if item_id:
item_url = 'https://item.szlcsc.com/' + item_id + '.html'
if item_url not in self.bloomfilter:
self.bloomfilter.add(item_url)
self.__url_queue.put(item_url)
page = page + 1
以上代码通过类似 https://list.szlcsc.com/catalog/312.html 的网址解析出该页面所有的 productId,并拼接成完整的产品链接,将链接放入待爬队列中。
Explore more like this


外行学 python 爬虫 第十一篇 数据可视化
在 外行学 Python 爬虫 第九篇 读取数据库中的数据 中完成了使用 API 从数据库中读取所需要的数据,但是返回的是 JSON 格式,看到的是一串的字符串数据不是很好理解,这篇将介绍如何将数据进行可视化。

外行学 python 爬虫 第十篇 爬虫框架 Scrapy
前面几个章节利用 python 的基础库实现网络数据的获取、解构以及存储,同时也完成了简单的数据读取操作。在这个过程中使用了其他人完成的功能库来加快我们的爬虫实现过程,对于爬虫也有相应的 python 框架供我们使用「不重复造轮子是程序员的一大特点」,当我们了解爬虫的实现过程以后就可以尝试使用框架来完成自己的爬虫,加快开发速度。
Comments