外行学 python 爬虫 第八篇 功能优化

keinYe 完成于

.
在前一篇中讲了如何开启多线程来加快爬虫的爬取速度,本节主要对爬虫爬取内容机型优化,将生产商信息单独独立出来作为一张数据库表,不再仅仅是存储一个生产商的名称,同时保存了生产商的网址和介绍。
解析生产商信息
针对生产商页面的信息的解析方法请参考 外行学 Python 爬虫 第三篇 内容解析,在这里我们只需要按照相同的方法解析出生产商名称、网址、简介等信息即可,生产商数据表内容如下:
class Brands(Base, CRUDMixin):
__tablename__ = 'brands'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(100), nullable=False, unique=True)
url = Column(String(100))
desc = Column(Text)
materials = relationship('Materials', backref='brands')
在完成数据表和网页信息解析相关的内容后,我们需要将生产商页面的 url 加入爬虫的有效 url 中,在整个程序中使用正则表达式来判断一个 url 是否是一个有效的 url,正则表达式的规则如下:
r'https?://(www|list|item).szlcsc.com(/(catalog|brand))?(/[0-9]*)?.html'
在 python 使用 re 模块来处理正则表达式
该表达式可以过滤出一下网址:
'https://www.szlcsc.com/catalog.html'
'https://list.szlcsc.com/catalog/542.html'
'https://item.szlcsc.com/22931.html'
'https://www.szlcsc.com/brand.html'
'https://list.szlcsc.com/brand/11442.html'
以上网址包含了元件目录、元件列表、元件详情、生产商列表、生产商详情等页面。
一下 url 校验的函数,函数接收正则表达式和 url 两个参数
def check_url(self, regex, url):
if regex is None or url is None:
return False
if re.match(regex, url) is None:
return False
return True
由于元件信息和生产商信息相互关联,且一个生产商可以对应多个元件,因此需要先获取生产商的信息,在获取网页中的 url 时,需要先对生产商的 url 进行识别,然后在识别元件的 url,相关的函数如下:
def __find_url(self, current_url, html):
for link in html.find_all(name='a', href=re.compile(REGEX_EXP_BRAND_LIST)):
url = link.get('href')
if not self.url_in_bloomfilter(url):
if Crawler.url_queue.qsize() < Crawler.max_url_count:
self.url_add_bloomfilter(url)
Crawler.url_queue.put(url)
if self.check_url(REGEX_EXP_CATLOG_LIST, current_url):
if Crawler.url_queue.qsize() > Crawler.max_url_count:
Crawler.url_queue.put(current_url)
else:
self.get_product_item_url(current_url)
for link in html.find_all(name='a', href=re.compile(REGEX_EXP_ALL)):
url = link.get('href')
if not self.url_in_bloomfilter(url):
if Crawler.url_queue.qsize() < Crawler.max_url_count:
self.url_add_bloomfilter(url)
Crawler.url_queue.put(url)
整个程序的执行流程
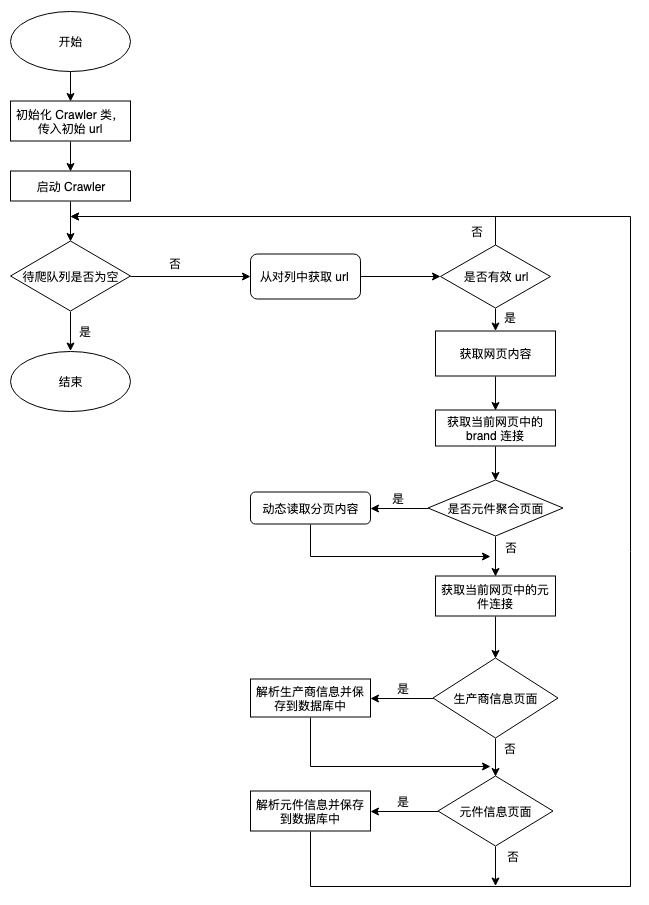
真个程序执行后,在数据库中可以看到生产商、元件信息、元件价格等三张数据表,后面可以对着三个表的数据进行分析。
Explore more like this


外行学 python 爬虫 第十一篇 数据可视化
在 外行学 Python 爬虫 第九篇 读取数据库中的数据 中完成了使用 API 从数据库中读取所需要的数据,但是返回的是 JSON 格式,看到的是一串的字符串数据不是很好理解,这篇将介绍如何将数据进行可视化。

外行学 python 爬虫 第十篇 爬虫框架 Scrapy
前面几个章节利用 python 的基础库实现网络数据的获取、解构以及存储,同时也完成了简单的数据读取操作。在这个过程中使用了其他人完成的功能库来加快我们的爬虫实现过程,对于爬虫也有相应的 python 框架供我们使用「不重复造轮子是程序员的一大特点」,当我们了解爬虫的实现过程以后就可以尝试使用框架来完成自己的爬虫,加快开发速度。
Comments