外行学 python 爬虫 第十篇 爬虫框架 Scrapy


.
前面几个章节利用 python 的基础库实现网络数据的获取、解构以及存储,同时也完成了简单的数据读取操作。在这个过程中使用了其他人完成的功能库来加快我们的爬虫实现过程,对于爬虫也有相应的 python 框架供我们使用「不重复造轮子是程序员的一大特点」,当我们了解爬虫的实现过程以后就可以尝试使用框架来完成自己的爬虫,加快开发速度。
在 python 中比较常用的爬虫框架有 Scrapy 和 PySpider,今天针对 Scrapy 爬虫框架来实现前面几篇所实现的功能。
准备工作
首先需要在系统中安装 Scrapy 「也可以使用 virtualenv 创建一个虚拟环境」,可以通过以下方式来安装 Scrapy。
#使用 pip 来安装 Scrapy
pip install Scrapy
Scrapy 安装完成以后,通过以下方式来创建一个基本的 Scrapy 项目。
scrapy startproject project
编写你的爬虫
在 Scrapy 中所有的爬虫类必须是 scrapy.Spider 的子类,你可以自定义要发出的初始请求,选择如何跟踪页面中的链接,以及如何解析下载的页面内容以提取数据。
一个基础爬虫
第一个爬虫我们选择使用 scrapy.Spider 作为父类,建立一个简单的单页面爬虫。建立一个 Scrapy 爬虫文件可以直接在 spider 目录下新建文件然后手动编写相关内容,也可以使用 scrapy genspider [options] <name> <domain> 命令来建立一个空白模板的爬虫文件,文件内容如下:
# -*- coding: utf-8 -*-
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['domain.com']
start_urls = ['http://domain.com/']
def parse(self, response):
pass
如上所示 TestSpider 继承自 scrapy.Spider,并定义了一些属性和方法:
- name:当前爬虫的名称,用来标识该爬虫。
- allowed_domains:当前爬虫所爬取的域名。
- start_urls:爬虫将顺序爬取其中的 url。
- parse:爬虫的回调函数,用来处理请求的响应内容,数据解析通常在该函数内完成。
我们使用 scrapy.Spider 来建立一个爬取「立创商城」上所有元件分类的爬虫,爬虫名称命名为 catalog,将 start_urls 更换为 https://www.szlcsc.com/catalog.html,下面贴出解析函数的代码
def parse(self, response):
catalogs = response.xpath('//div[@class="catalog_a"]')
for catalog in catalogs:
catalog_dl = catalog.xpath('dl')
for tag in catalog_dl:
parent = tag.xpath('dt/a/text()').extract()
childs = tag.xpath('dd/a/text()').extract()
parent = self.catalog_filter_left(self.catalog_filter_right(parent[0]))
yield CatalogItem(
parent = parent,
child = None,
)
for child in childs:
yield CatalogItem(
parent = parent,
child = self.catalog_filter_right(child),
)
通过以下命令来启动爬虫,观察爬虫的爬取过程及结果。
scrapy crawl catalog
递归爬虫
上一小节中实现了一个简单的单页面爬虫,它仅能访问在 start_urls 中列明的页面,无法从获取的页面中提取出链接并跟进。scrapy 通过 CrawlSpider 来实现按照一定的规则从当前页面中提取出 url,并跟进爬取。可以通过命令 scrapy genspider -t crawl test domain.com 来指定使用 CrawlSpider 建立爬虫。生产文件内容如下:
mport scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TestSpider(CrawlSpider):
name = 'test'
allowed_domains = ['domain.com']
start_urls = ['http://domain.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
基于 CrawlerSpider 的爬虫不同之处在于多了一个 rules 的属性,该属性定义了如何从网页中提取 url,并使用指定的回调函数来处理爬取结果。
使用递归爬虫来实现「立创商城」中生产商的爬取在合适不过了,以下贴出相应的链接提取规则和处理函数。
rules = (
Rule(LinkExtractor(allow=(r'https://list.szlcsc.com/brand/[0-9]+.html', )), callback='parse_item', follow=False),
)
def parse_item(self, response):
brand_info_logo = response.xpath('//div[@class="brand-info-logo"]')
brand_info_text = response.xpath('//div[@class="brand-info-text"]')
name = brand_info_logo.xpath('h1[@class="brand-info-name"]/text()').extract()
url = brand_info_logo.xpath('descendant::a[@class="blue"]/@href').extract()
desc = brand_info_text.xpath('div[@class="introduce_txt"]//text()').extract()
...
return BrandItem(
name = name,
url = url,
desc = desc_text,
)
动态数据处理
爬虫在处理的过程中不可避免的会遇到动态数据的处理,「立创商城」中元件的列表页面的翻页即是通过 ajax 来实现的,如果仅仅使用上一节中的递归爬取的方法,有很多的元件将会被漏掉,在这里可以使用 scrapy 模拟 post 方法来实现翻页的效果。
在 scrapy 中向网站中提交数据使用 scrapy.FormRequest 来实现。FormRequest 类扩展了基 Request 具有处理HTML表单的功能。通过 FormReques 向翻页 API 上提交新的页面信息,从而获取新页面中的 Json 数据,通过解析 Json 数据来获取整个网站中的元件信息。
动态翻页所需要的 API 及提交数据的格式在 外行学 Python 爬虫 第六篇 动态翻页 中做过分析,可以在那里找到相关的信息。
通过 FormRequest 来指定 url、提交数据、返回数据的回调函数等,具体实现如下:
yield scrapy.FormRequest(url=product_post_url,
formdata=post_data,
callback=self.json_callback,
dont_filter = True)
由于 Scrapy 中自带了 url 去重功能,因此需在 FormRequest 中设置
dont_filter = True,否则 FormRequest 只会执行一次。
数据的存储
Scrapy 使用 Item 来定义通用的输出数据格式,数据通过 Item 在 Scrapy 的各个模块中进行传递,以下是一个简单的 Item 定义:
class BrandItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
desc = scrapy.Field()
数据的处理通常在 Pipeline 中进行,在爬虫中获取的数据将通过 Item 传递到 Pipeline 的 process_item 方法中进行处理,以下代码实现了将数据存在 sqlite 数据库中。
class BrandPipeline(object):
def __init__(self, database_uri):
db.init_url(url=database_uri)
self.save = SaveData()
@classmethod
def from_crawler(cls, crawler):
return cls(
database_uri=crawler.settings.get('SQLALCHEMY_DATABASE_URI'),
)
def process_item(self, item, spider):
if spider.name == 'brand':
self.save.save_brand(brand=item)
raise DropItem('Drop Item: %s' % item)
return item
其中 from_crawler 方法用来冲 setting 文件中获取数据库链接。
Item 按照在 setting 中定义的优先级在各个 Pipeline 中进行传递,如果在某个 Pipeline 中对该 Item 处理完成后续无需处理,可以使用 DropItem 来终止 Item 向其他的 Pipeline 传递。
反爬处理
爬虫不可避免的会遇到网站的反爬策略,一般的反爬策略是限制 IP 的访问间隔,判断当前的访问代理是否总是爬虫等。
针对以上策略,可以通过设置两个请求之间间隔随机的时间,并设置 User-Agent 来规避一部分的反爬策略。
设置请求间隔随机时间的中间件实现如下:
class ScrapyTestRandomDelayMiddleware(object):
def __init__(self, crawler):
self.delay = crawler.spider.settings.get("RANDOM_DELAY")
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
delay = random.randint(0, self.delay)
spider.logger.debug("### random delay: %s s ###" % delay)
time.sleep(delay)
然后在 setting 文件中启用该中间件。
RANDOM_DELAY = 3
DOWNLOADER_MIDDLEWARES = {
'scrapy_test.middlewares.ScrapyTestDownloaderMiddleware': None,
'scrapy_test.middlewares.ScrapyTestRandomDelayMiddleware': 999,
}
User-Agent 可以直接在 setting 文件中修改,在我们的浏览器中查看当前浏览器的 User-Agent,将 Scrapy 的 User-Agent 设置为浏览器的 User-Agent。以下是 Chrome 流量中 User-Agent 的查找方法。
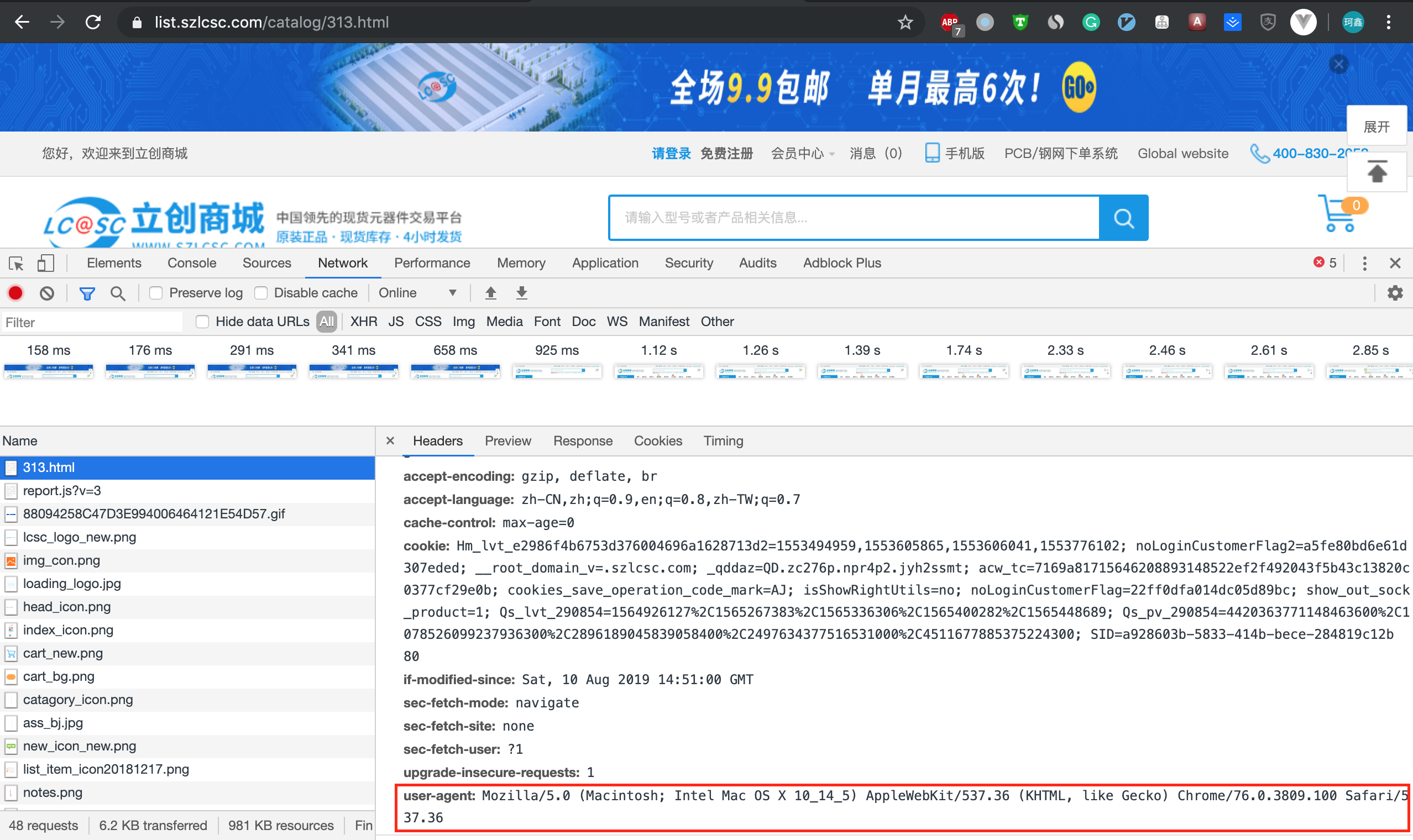
前面都没有提到过网站的反爬虫,这次提到的原因是真的被「立创商城」给限制访问了。
运行爬虫
今天将前面所完成的爬虫功能使用 Scrapy 进行了一个重构,catalog 使用的是单页爬虫用来获取原件的分类信息,brand 是一个递归爬虫用来获取原件生产商信息,product 是一个通过 post 动态获取 json 并解析的爬虫,主要用来获取所有元件的信息。
有多个爬虫需要运行,可以使用以下方法逐个运行爬虫
# -*- coding:utf-8 -*-
import os
os.system("scrapy crawl brand")
os.system("scrapy crawl catalog")
os.system("scrapy crawl product")
如果想同时运行多个爬虫,以下方法是个不错的选择
# -*- coding:utf-8 -*-
from scrapy.utils.project import get_project_settings
from scrapy.crawler import CrawlerProcess
def main():
setting = get_project_settings()
process = CrawlerProcess(setting)
process.crawl(brand)
process.crawl(catalog)
process.crawl(product)
process.start()
Explore more like this


外行学 python 爬虫 第十一篇 数据可视化
在 外行学 Python 爬虫 第九篇 读取数据库中的数据 中完成了使用 API 从数据库中读取所需要的数据,但是返回的是 JSON 格式,看到的是一串的字符串数据不是很好理解,这篇将介绍如何将数据进行可视化。

SQLAlchemy 数据表自关联
我们说数据表关系时,默认说的是数据表之间的关系「一对多、一对一、多对多等等」。而在实际应用中常常会遇到数据表内的关联,比如现在互联中的一个名词「关注者」和「被关注者」,他们都在用户范围内,只是两个用户之间的关系。
Comments